Photo by Prateek Katyal on Unsplash
If the machine learning projects are icebergs, then the parts that are underwater are the labelling and other data efforts that go into the project. The good news is techniques like transfer learning and active learning could help in reducing the effort.
Active learning has been part of the toolbox of ML industry practitioners for a while but rarely covered in any of the data science / ML courses. Reading the book Human in the loop machine learning by Robert Munro, helped me formalise some ( and helped me learn many ) of the active learning concepts that I had been using intuitively for my ML projects.
The intent of this article is to introduce you to a simple active learning method called ‘Uncertainty sampling with entropy’ and demonstrate its usefulness with an example. For the demonstration, I have used Active learning to utilize only 23% of the actual training dataset ( ATIS intent classification dataset) to achieve the same result as training on 100% of the dataset.
Too curious? Jump straight to the demo. Want to first understand how it works? Read on.
What is active learning?
Active learning is about training our models preferentially on the labelled examples that could give the biggest bang for our buck rather than on the examples with very less “learning signal”. The estimation of an example’s learning signal is done using the feedback from the model.
This is akin to a teacher asking a student about the concepts that she is hazy about and giving preference to those concepts, rather than teaching all of the curricula.
Since active learning is an iterative process, you would have to go through multiple rounds of training. Steps involved in active learning are:
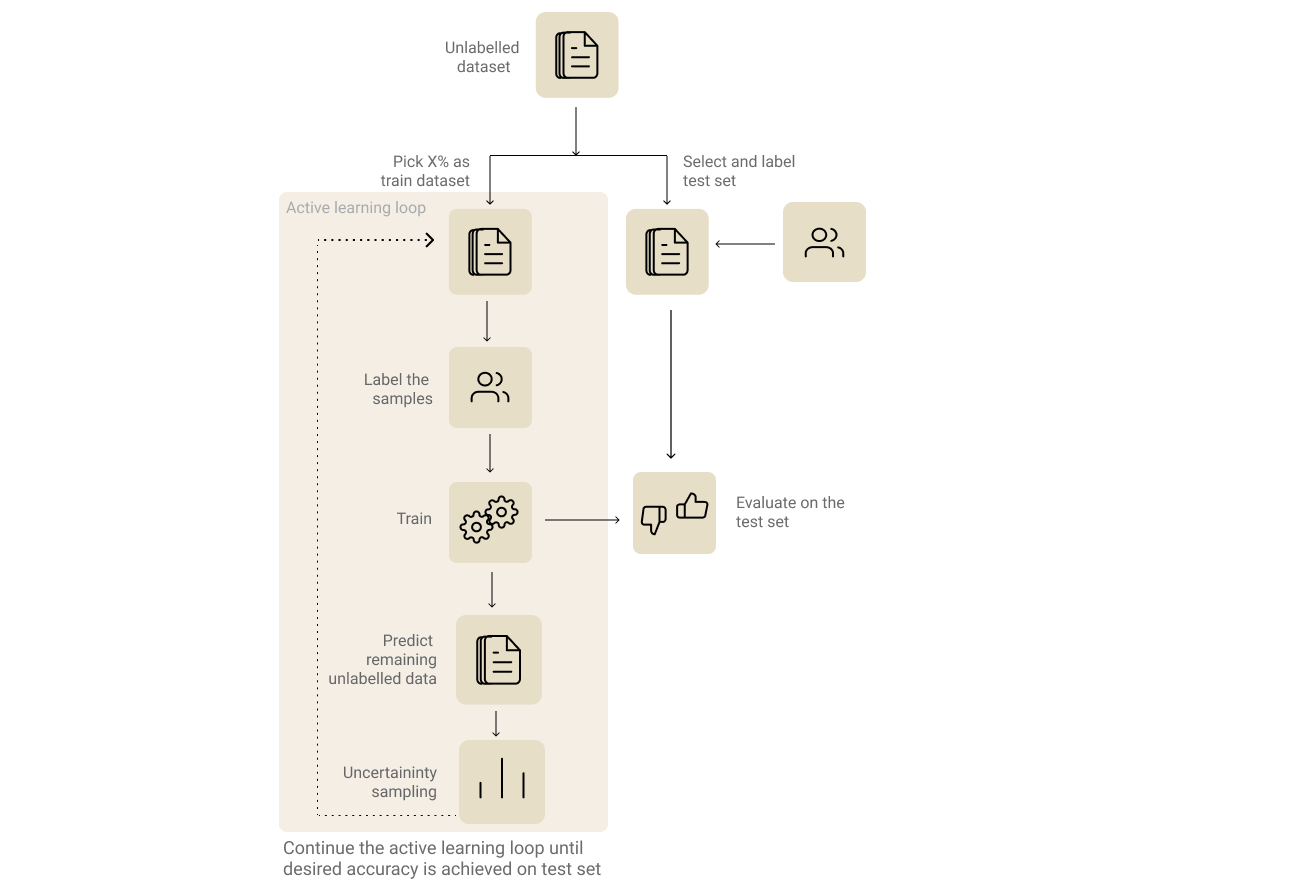
Active learning process
1. Identify and label your evaluation dataset.
It goes without saying that choosing an evaluation set is the most important step in any machine learning process. This becomes even more crucial when it comes to active learning since this will be our measure of how well our model performance improves during our iterative labelling process. Furthermore, it also helps us decide when to stop iterating.
The straight forward approach would be to randomly split the unlabelled dataset and pick your evaluation set from that split dataset. But based on the complexity or the business need, it is also good to have multiple evaluation sets. For example, If your business need dictates that a sentiment analysis model should handle sarcasm well, you could have two separate evaluation sets — one for generic sentiment analysis and other for sarcasm specific samples.
2. Identify and label your initial training dataset.
Now pick X% of the unlabeled dataset as the initial training dataset. The value of X could vary based on the model and the complexity of the approach. Pick a value that is quick enough for multiple iterations and also big enough for your models to train on initially. If you are going with a transfer learning approach and the distribution of the dataset is close to the pre-training dataset of the base model, then a lower value of X would be good enough to kick start the process.
It would also be a good practice to avoid class-imbalance in the initial training dataset. If it’s an NLP problem, you could consider a keyword-based search to identify samples from a particular class to label and maintain class balance.
3. Training Iteration
Now that we have the initial training and evaluation dataset, we can go ahead and do the first training iteration. Usually, one cannot infer much by evaluating the first model. But the results from the step could help us see how the predictions improve over the iterations. Use the model to predict labels of the remaining unlabelled samples.
4. Choose the subset of samples to be labelled from the previous step.
This is a crucial step where you select samples with the most learning signals for labelling processes. There are several ways to go about doing it (as explained in the book). In the interest of brevity, we will see the method that I felt to be most intuitive of all — Uncertainty sampling based on entropy.
Entropy-based Uncertainty Sampling :
Uncertainty sampling is a strategy to pick samples that the model is most uncertain/confused about. There are several ways to calculate the uncertainty. The most common way is to use the classification probability (softmax) values from the final layer of the neural network.
If there is no clear winner (i.e all the probabilities are almost the same), it means that the model is uncertain about the sample. Entropy exactly gives us a measure of that. If there is a tie between all the classes, entropy of the distribution will be high and if there is a clear winner amongst the classes, the entropy of the distribution will be low.
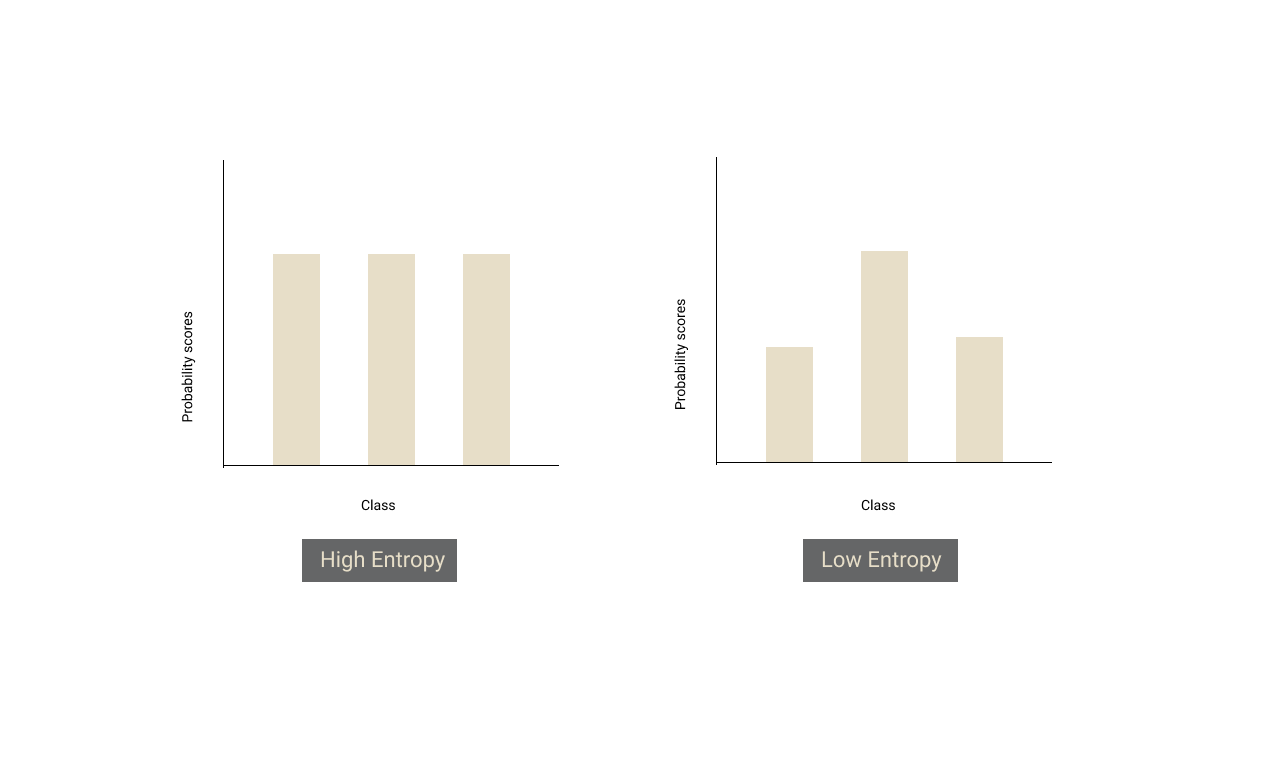
From the model’s predictions of the unlabelled dataset, we should sort the samples in descending order of entropy and pick some Y% of top samples to annotate.
5. Rinse & Repeat :
We need to append the training dataset from this iteration with the new samples that we labelled and repeat the process from step 3, until we reach the desired performance on our evaluation set or our evaluation performance plateaus.
Demo
For the sake of experiment and demonstration, we will use ATIS intent classification dataset. Let’s consider the training dataset as unlabelled. We start by taking a random 5% of the labelled training dataset for our first iteration. At the end of each iteration, we use entropy-based uncertainty sampling to pick top 10% of the samples and use their labels (simulating the annotation process in the real world) for training in the next iteration.
To evaluate our models during each iteration of active learning, we also take the test set from the dataset since the data in the test set is already labelled.
Demo and code is available in the notebook below: Google Colaboratory colab.research.google.com
References :
-
David D. Lewis and William A. Gale. 1994. A Sequential Algorithm for Training Text Classifiers. SIGIR’94, https://arxiv.org/pdf/cmp-lg/9407020.pdf
Thanks to Sriram Pasupathi for taking a greater effort in proofreading this article than what it took me to write this article 🙏
**P.S: I would be really glad to hear your feedback on this article, that would also push me to write the other articles in the series on “How to do more with less data” **👋