It is well-established that LLMs are useful at coding. With the ongoing advancement in their code refinement abilities with execution feedback, and increasing context length, coupled with decreasing costs,it is becoming apparent that LLMs will play a significant role in software development and likey to surpass human contribution.
Having said that, software development is complex and involves many aspects that LLMs still struggle with, like effectively solving repository level tasks, collaboration, using and integrating with our existing workflows and tooling.
Just as syntax highlighting , code completions , tool tips with code hints , linting in an IDE help improve coding efficiency for humans, interfaces purpose built for agents would help improve the coding success rate of LLMs. These interfaces decide how a code context or an execution output context can be shared with LLMs effectively for their usage. These interfaces are a step towards bridging the gap in current abilities of LLMs in completing SWE tasks.
In this blog post, we will explore some of the latest agent interfaces that have been used in state-of-the-art software engineering (SWE) agents
These interfaces can be broadly split into two high-level categories:
- Localization of the code to change ( Context retrieval )
- Patch generation ( Making the change required for a fix or new feature )
Localization of the code to change:
The first step in fixing or implementing a new feature to a repository is to understand the overall structure of the repository and locate the files and lines to be changed in the repository. Giving the context of a full repo is inefficient and impractical for moderately sized repos. Here we discuss some of the approaches to condense the repository structure and localize the location of code change to be done.
-
Repository tree structure:
Agentless (Xia et al. 2024) and Repopilot create a high-level tree representation of the directory and files in the repository by recursively traversing from the root folder to each code file. This is fed to the LLM as an initial step for it to understand the repository and generate probable candidate files for it to start with the editing process.

Example of a repository structure
-
Repository map:
Aider uses a richer representation called repo map than the basic repository tree structure, to provide repository context to the LLMs. The repo map has a list of files in the repository along with the important symbols and their definition in each file. This is done by analysing the AST of the code files with tree-sitter .
This context can also easily become very large for a repository with tens to hundreds of files. Aider cleverly addresses this challenge by using a graph ranking algorithm to include only the most relevant and important files within a context budget.
aider/coders/base_coder.py: ⋮... │class Coder: │ abs_fnames = None ⋮... │ @classmethod │ def create( │ self, │ main_model, │ edit_format, │ io, │ skip_model_availabily_check=False, │ **kwargs, ⋮... │ def abs_root_path(self, path): ⋮... │ def run(self, with_message=None): ⋮... aider/commands.py: ⋮... │class Commands: │ voice = None │ ⋮... │ def get_commands(self): ⋮... │ def get_command_completions(self, cmd_name, partial): ⋮... │ def run(self, inp): ⋮... -
Search tools :
SWE-agent (Yang et al. 2024) , OpenDevin (Wang et al. 2024) and AutoCodeRover (Zhang et al. 2024) use bash and python-based utilities as tools to let agents search through and understand the files. The utilities are used by agents to perform high-level searches like searching a directory with keyword , searching a file and more specific searches like searching for a class , method etc.
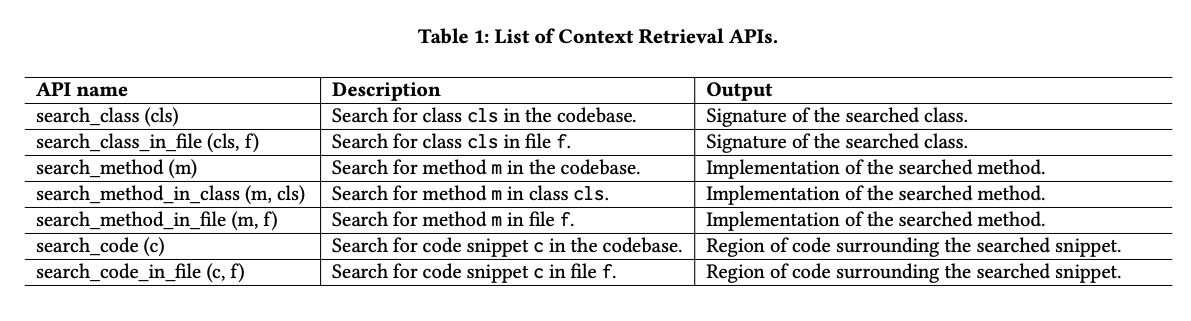
This helps in reducing the context provided to the agents. Rather than us deciding the context to be fed to the agents, with the search tools the agents decide the context needed to perform an action.
Yang et al. 2024 further control the context by restricting the search results to almost 50 results and if the results are not satisfactory, the model is prompted to search with a more specific query. The authors find that using these search tools improves the pass rate of tasks.
-
File context:
Similar to repo context, It is inefficient to provide the full context of a file to the agent at once. SWE-Agent (Yang et al. 2024) and OpenDevin (Wang et al. 2024) use several utilities to control the context.
Open: The file viewer presents a window of at most 100 lines of the file at a timescroll_downandscroll_up: Move the window up and downgoto: access a specific line
The code in the file viewer is enumerated with line numbers. This helps the model to use the correct line numbers while editing the file.
The file viewer has important additional details like the full path of the open file, the total number of lines in the file, and the number of lines omitted before and after the current window. This helps the model to understand that there are more lines in the file and it can scroll up or down to access further context when needed.
-
Localisation from the repository to code location:
-
To localize the code lines to be changed from the repository level context Agentless (Xia et al. 2024) takes a multistep approach. They first pass the repository structure ( discussed above) to the model and ask it to generate the Top N most probable files that should be edited for a given feature or a fix.
The skeleton ( important symbols and definition) of these shortlisted files is provided as context to further shortlist the specific list of classes and functions that should be edited. The complete code of these shortlisted locations is prompted to the model for editing.
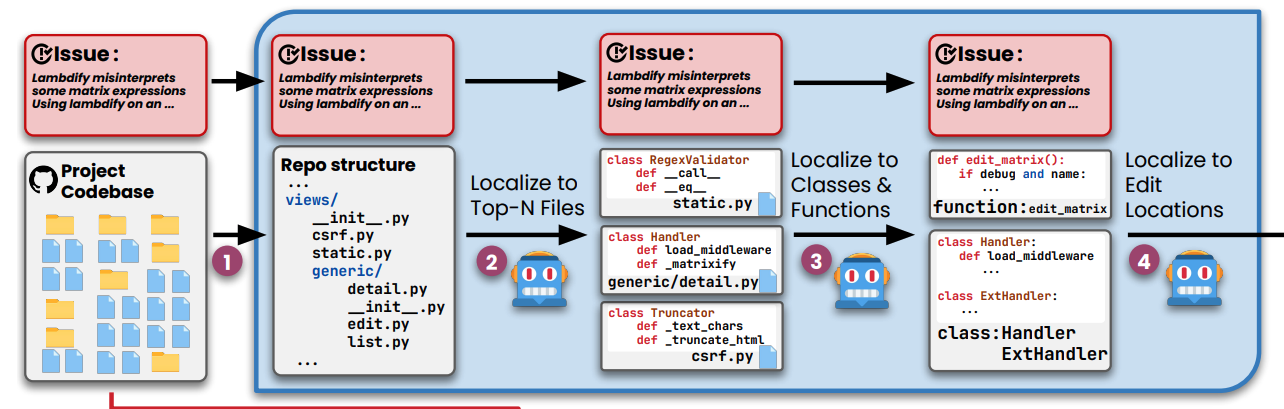
- Aider takes a more practical and human-in-the-loop approach to file localisation, The files to be edited are expected to be added to the Aider’s chat by the user. This workflow would avoid failure modes of the wrong file being edited or the model getting stuck in editing the wrong file.
-
-
Spectrum-based Fault Localization (SBFL):
Autocoderover (Zhang et al. 2024) uses an external tool to suggest probable locations of fault using a method called Spectrum-based Fault Localization . Given a test suite containing passing and failing tests, SBFL considers control-flow differences in the passing and failing test executions and assigns a suspiciousness score to different program locations. These suspicious locations are fed to the LLM to further identify the most likely locations of errors

SBFL from Autocoderover (Zhang et al. 2024))
Patch generation:
The next step after localisation is to generate a code change to fix or add a new feature. A trivial approach to this would be to generate the code file from scratch (as a whole) for every edit, but this is inefficient, time consuming and can be limited by the context. Let’s discuss more efficient alternatives for edit generation in this section.
-
Editing with line numbers :
SWE-agent (Yang et al. 2024) ( and previously OpenDevin (Wang et al. 2024) ) uses line numbers to specify the range of lines that are to be edited. The line range in the file is replaced with the code specified in the command.

Sample edit command from SWE-AGENT, the line 1475 in the code file is replaced with the code in the command
This method is efficient in terms of token usage and could also lead to a higher success rate of edits getting executed. But it also leads to some of the common failure modes:
- Models are bad at tracking line numbers: Even if the file context interface is always shown with line numbers, with consecutive edits throughout the task lifecycle the line numbers change often. This results in the model invoking the command with wrong line numbers resulting in incorrect edits and syntax errors.
- Actions do not always match the intention: This is not only specific to this editing approach, but it is prevalent with this one. The model would intend to change a set of lines ( like an
ifblock) but it would end up specifying the line range of just few lines of the block instead of the complete ones ( like just theifcondition line ) leading to errors.
-
Line diff format:
An alternate approach is to let the model generate edits in unified diff format , which is a standard way of displaying the changes between code files and the models are more likely to be familiar with this approach due to its familiarity during pretraining. However, this approach necessitates the model to generate several unchanged lines before and after the actual change lines.

An example of Unified diff format from OctoPack: Instruction Tuning Code Large Language Models. Muennighoff et al. 2023
Muennighoff et al. 2023 introduce a simplified diff format called line diff format. Requiring only the lines of change to be shown ( along with line numbers) instead of additional lines as in unidiff format. Muennighoff et al. 2023 show that fine-tuning models with this format perform better than the unidiff format on the zero-shot HumanEvalFix dataset.

An example of line diff format from OctoPack: Instruction Tuning Code Large Language Models. Muennighoff et al. 2023
-
Search and replace diff string format:
Aider uses another diff string-based edit format which is shown to perform the best in their code editing benchmark. The format uses a fenced code block that specifies the file name, and lines of code to be replaced followed by new code lines in the replace block.
Even though this approach consumes a lot more tokens than the line number-based approach, it seems to handle the common failures better.
# Here are the changes you requested to demo.py: demo.py <<<<<<< SEARCH print("hello") ======= print("goodbye") >>>>>>> REPLACEBut from my personal experience, this approach is also not perfect and also leads to some of the common failure modes:
- Edit failures due to additional lines: When the models generate the code in the search block, it sometimes hallucinates additional lines which are not in the original file. This leads to edits not being applied because of a lack of exact match with the original code.
- Edit failures due to missing lines: This is the opposite of the above case, the model sometimes fails to mention the empty new lines or comments from the original file leading to no exact match
- Actions do not always match the intention: Even this approach has the issue of the model missing the full code block that it intends to change, mentioning only the partial lines.
-
Linting before applying edits:
SWE-agent (Yang et al. 2024) study that linting the code to check for syntax errors before applying the code improves the overall pass rate by 3% on SWE-bench tasks.
)](/assets/images/lint_flow.png)
Examples with and without linting from SWE-agent (Yang et al. 2024)

-
Post edit:
SWE-agent (Yang et al. 2024) and OpenDevin (Wang et al. 2024) show the edited location along with a window of a few top and bottom lines to the model after the edit is applied. This helps the model to look for any duplicates or mistakes that are introduced in the edit and rectify the same via the next actions
Example of a file viewer shown after file edit with a prompt to followup with further actions on edit mistakes
Open challenges:
In conclusion, here are some of the open challenges or limiting factors for the models in handling SWE tasks:
- File edits are messy: With the current capabilities and existing interfaces ( more so) the file editing process is messy and inefficient compared to code generation from scratch. It goes through numerous iterations and with more tries the chances of the model getting stuck in a loop increases.
- Extending the context from programs to systems: The current approaches are more focussed on the models to work at a program/file level but the capabilities to interact and design at the system level and architect a software system are still missing.
- Leveraging human developer interfaces: With improving multi-modal abilities of the models and models entering our desktops ( this and this ). The agent interface could be just a transitioning phase till the models can truly leverage the years of dev tooling that have been honed by humans.
Citation
@article{umapathi2024agentinterfaces,
title = "Agent Interfaces: Bridging LLMs and Software Engineering",
author = "Umapathi, Logesh Kumar",
journal = "logeshumapathi.com",
year = "2024",
month = "Aug",
url = "https://logeshumapathi.com/blog/2024/08/03/agent-interfaces.html"
}
References
- Xia et al. 2024. “Agentless: Demystifying LLM-based Software Engineering Agents”
- Gauthier, P. “Aider”.
- Muennighoff et al. (2023). “OctoPack: Instruction Tuning Code Large Language Models”
- Yang et al. 2024. “SWE-Agent: Agent-Computer Interfaces Enable Automated Software Engineering”
- Wang et al. 2024. “OpenDevin: An Open Platform for AI Software Developers as Generalist Agents.”
- Zhang et al. 2024. “AutoCodeRover: Autonomous Program Improvement”
- “RepoPilot: Multi-Agent Coding Assistant that Understand Your Codebase”