Cameras are everywhere — in our homes, on our streets, in stores, at intersections, in care centers, in mobile devices and across the systems we rely on every day. Yet most of them are still just passive recordings: endless hours of footage that no one watches unless something has already gone wrong.
What if live video systems could do more than just record? What if they could understand context, reason over events, and alert only when something genuinely important happens? — even across thousands of hours of uneventful footage? Better yet, what if they could anticipate important events before they fully unfold?
A system like that could make streets safer, help elders live more independently, give parents greater peace of mind, and make homes more secure.
Vaan is a step in that direction. Its goal is to be a flexible, promptable system for monitoring live video streams and alerting users when important events of interests happen.
How it works
Problem
The core problem in live video understanding is sparsity. In most real-world streams, the events we care about are rare.
A fall, an accident, a theft, an abandoned item, or an unusual event may happen only once in thousands of hours of footage. In many streams, it may never happen at all. And yet the system has to stay ready, keep watching, and make the right call in real time. This makes the problem fundamentally different from the typical short-context perception tasks that multimodal LLMs have shown strong capabilities for.
Because of this, we cannot process the entire stream with multimodal LLMs in the traditional way (limitations: context windows , latency and the cost ). At the same time, we still want to leverage the world understanding and reasoning capabilities of multimodal LLMs and to have the flexibility of handling variety of events just with text based queries and not complex configuration or event specific pipelines.
Approach
Inspiration
If we squint a little, this problem looks very similar to the one faced by live voice assistants. Live voice assistants deal with a comparable challenge, though usually in a less extreme form. Where the signal of interest — user speech — is also sparse relative to the total duration of the stream.They must continuously determine when the user is speaking and when she is not.
This is why modern voice assistants built on top of general-purpose LLMs do not hand off transcript / raw audio continuously to the model. Instead, they use a staged pipeline that cheaply filters, segments, and validates candidate moments before escalating to a more capable and more expensive model.
Modern live voice assistant systems such as LiveKit Agents address this using a pipeline like the one shown below:
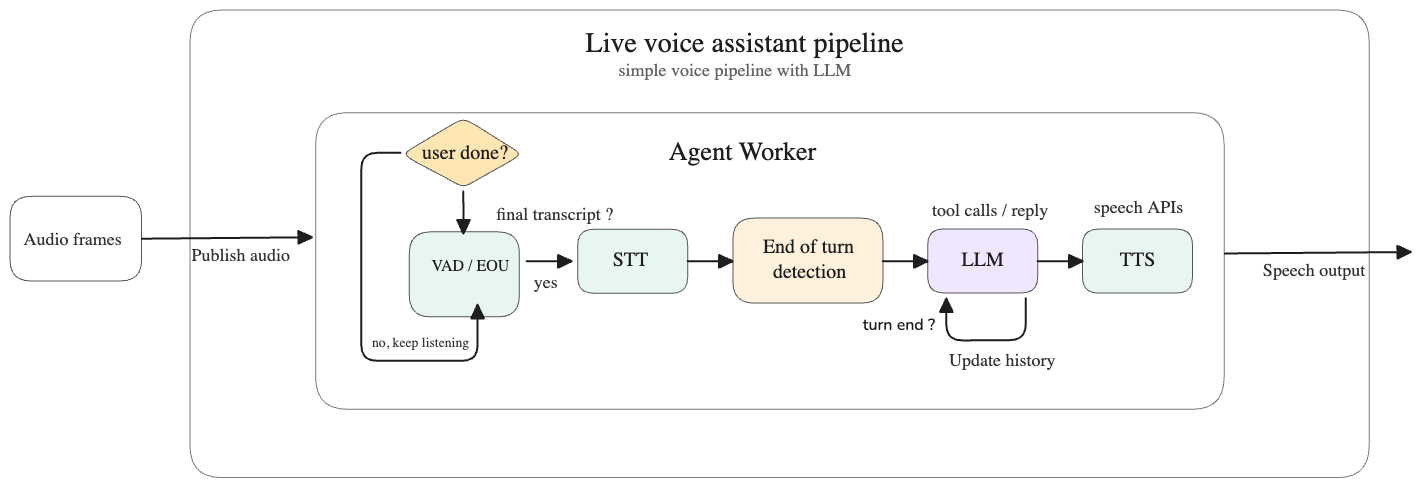
The key stages in that pipeline are:
- The audio stream is chunked and passed through a VAD (voice activity detection) model to determine whether the user is speaking, whether speech is ongoing, and whether the user has paused or finished speaking.
- Once a pause or end of speech is detected, the chunk is sent to a transcription model to generate text.
- A pause detected by VAD does not necessarily mean the user has completed their thought. For example: “I want to switch on the lights … (pause) in the dining room.” To avoid handing incomplete input to the LLM, an end-of-turn detection model is used to determine whether the transcript actually represents a complete user turn.
- Once the transcript is classified as complete and end-of-turn, it is passed to the LLM to generate a response.
- The response is then sent to a TTS (text-to-speech) model to produce audio output.
All of these steps are executed in a streaming manner to reduce both latency and context usage.
At a high level, the solution is to first use a cheap and fast mechanism to speculate whether an event of interest has occurred — in the voice assistant case, speech and turn detection — and then hand over only the relevant context to a more accurate but more expensive LLM for verification and response generation.
This is similar to what Vaan attempts to achieve for live video streams.
Solution
Vaan uses a relatively cheap and fast mechanism to speculate whether an event of interest may have occurred — using rerankers or embedding-based retrievers — and then accumulates the relevant context before passing it to a more accurate but more expensive LLM to verify the event and generate the required response.
Here is a high-level overview of the architecture:
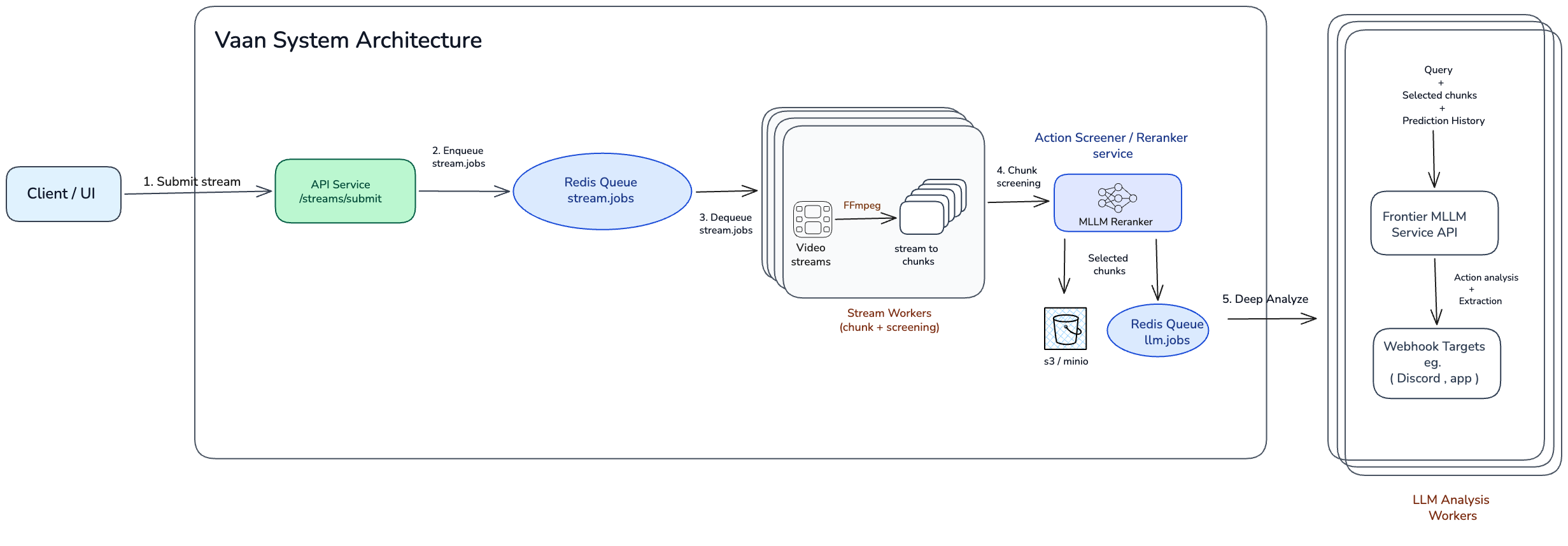
The key stages in this pipeline are:
- Once a stream is submitted, it is picked up by a stream worker for processing.
- The stream worker continuously chunks the video stream and passes each chunk to a screener (reranker) model to determine whether it is relevant to the trigger queries.
- If a chunk is identified as relevant, it is passed — along with neighboring chunks and other relevant context — to an LLM worker.
- The LLM worker reasons over the context, verifies the event and generates , extracting the required information for the alert.
Demo
We’ve put together a few demos of Vaan in action across very different real-world scenarios on a demo UI ( scroll horizontally over the videos to see them all ):
- Alerting when a baby has fallen down or may have gotten hurt.
- Alerting when uninvited wildlife shows up to raid the cat food.
- Alerting when Santa places a gift. (yes — Santa can’t sneak past this one 😅)
- Alerting when a vehicle accident occurs at an intersection.
- Alerting when a customer completes a checkout and walks away leaving their items behind.
- Alerting when a person / elderly falls down.
Getting started
Follow the instructions in the README to setup and get started.
Current limitations
-
The screener model uses
Qwen3-VL-Reranker-2Bto perform fast verification of chunks against the trigger queries. Out of the box, the model shows poor separability of classes: negative examples typically score below 53%, while positive examples are often only slightly higher, in the 55–57% range. This leaves little margin for reliable thresholding. -
We found that a threshold of 0.55 provides a good balance between precision and recall. However, the optimal threshold depends on the use case, so it may need to be adjusted based on your requirements. We recommend starting with 0.55 and calibrating it on your own data.
-
Current frontier multimodal LLMs are reasonably good at understanding videos and detecting actions, but they still do not perform as well on video reasoning tasks as they do on text reasoning tasks. To illustrate this, here are two examples of false positives.
-
In the first example, the model misinterprets overhead power lines on the street as fallen lines. It then combines this perception error with the presence of a police or emergency vehicle in the corner of the frame — likely from the aftermath of a different incident — and incorrectly classifies the scene as a car accident. The camera angle makes the power lines appear as though they are lying on the road, but for a human observer it is fairly obvious that this is not an accident scene.
-
In the second example, the trigger query is: “a customer completes a checkout and walks away leaving their items behind.” Here, the model fails to distinguish between empty shopping bags placed at the end of the checkout aisle and the customer’s actual items. As a result, it incorrectly concludes that the customer has walked away and left their items behind.
-
This behavior is not specific to any one model. We observe similar failure modes across current frontier multimodal LLMs with native video support, including gemini-3.1-pro-preview, gemini-3-flash-preview, qwen3.5-plus-02-15, and glm-4.6v.
Future directions
The current limitations outlined above are exactly what make this such an interesting and valuable problem to solve.
Some of the most exciting future directions are:
- Improve the screener model to achieve better separation between positive and negative examples, while making it more robust to variations in query phrasing, camera angle, and real-world noise.
- Move the screener closer to the source. Today, the screener is designed to run on serverless infrastructure on Modal, but over time we want it to run nearer to the camera — and eventually on-device where possible.
- Build systems that are more robust to the messiness of the real world. Real-world environments are noisy, ambiguous, and highly variable, and we want both the screening pipeline and the LLM layer to handle these variations more reliably.
- Create / curate a benchmark relevant to this problem to reliably evaluate the performance of the systems and future LLMs.
- System that can anticipate / predict events before they happen.
Contributing
We understand that this is a highly sensitive problem, which is exactly why we believe in building it in public.If any of these directions are interesting to you, please feel free to contribute to the project or share your thoughts and feedback in github issues or join the discord channel here. You can find the code and documentation in the GitHub repository.